
ウェブページ掲載されている画像をすべて一括でダウンロードしたいと思ったことはありませんか?
ウェブページ上の画像は、通常、目的の画像の上で右クリックして、「名前を付けて保存をする」などを選択して保存しますが、大量に画像が並んでいる場合には、少し面倒です。
そんなときはウェブページ全体を要素ごと全部一括でダウンロードする手法が有効です。
まずは、本題の前段としてその手順を紹介していきます。
ページを一括ダウンロードする方法
今回は「経済産業省」のホームページで試しています。
まずは、「Google Chrome」でアクセスしてみましょう。
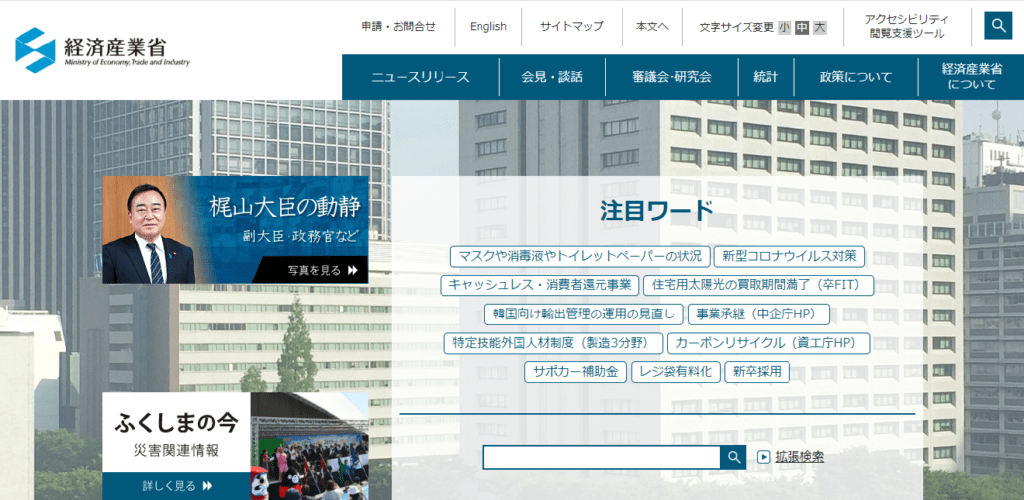
とりあえずページ上の適当なところ(背景以外の画像がない箇所)で右クリックし、「名前を付けて保存」を選択します。
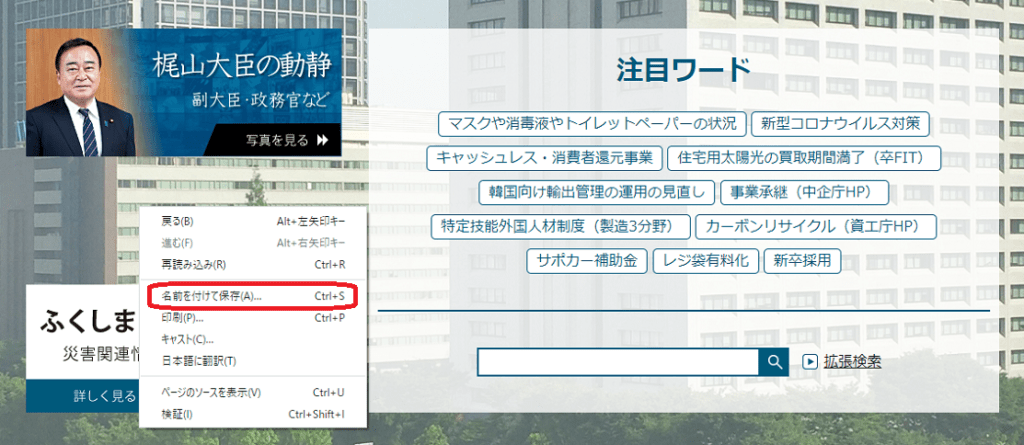
ファイルの種類が「ウェブページ、完全(*.html;*.html)」になっていることを確認して、「保存」をクリックするとダウンロードを開始します。
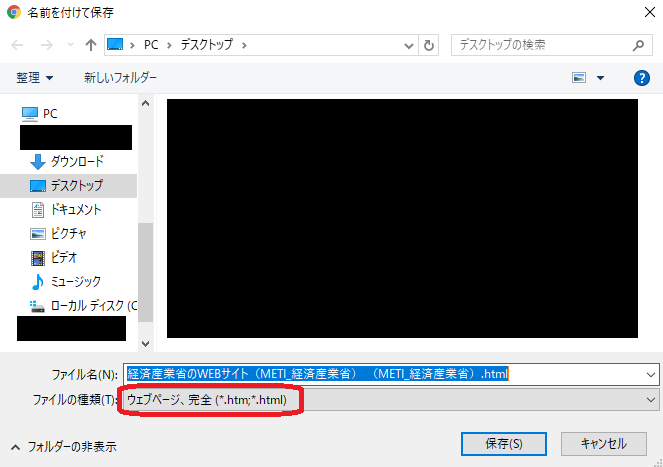
ダウンロードが完了すると、フォルダとHTMLファイルが生成されます。
フォルダを開くと以下のように、ウェブサイトで使用されている画像などのデータがすべて格納されています。
こうすれば、一枚ずつ保存する手間がかからなくて済みますね!

しかし、ここであることに気が付きます。
そうです、この記事のタイトルからも分かる通り、背景の高層ビルの画像がフォルダに入っていません。
ですので、次はいよいよ本題の「背景画像をダウンロードする方法」について解説していきます。
背景画像をダウンロードする方法
先ほど生成したフォルダ内にあるデータのうち、拡張子が「css」のものを開きます。
今回は、以下の2つのCSSファイルを開いていきます。
まずは、左側の「style(1).css」を開いていきます。

すると以下のような英語だらけの記述が表示されます。
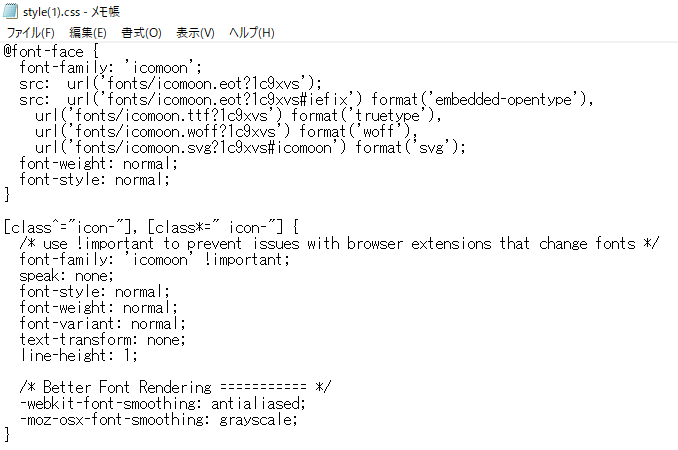
開いた後にやることは簡単で、それぞれのファイルの記述中から「background:url」のような記述を見つけていきます。「:」の前後はスペースが空いていることが多いので、それも含めて調べていきます。
まずは、ファイルを開いた状態で、「Ctrl」+「F」を同時押しします。
そして、検索する文字列の欄には「url」を入力し、「次を検索」をクリックします。
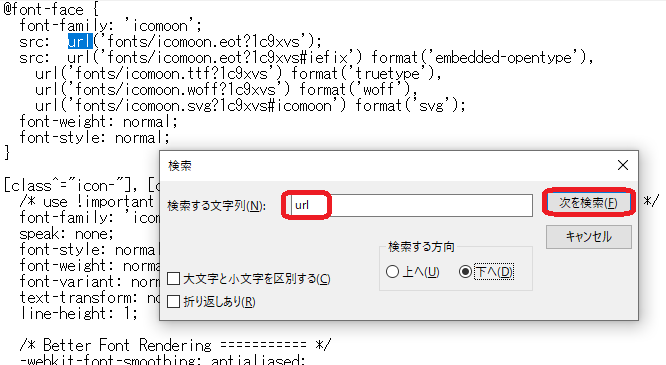
そうすると、「url」を含む文字列が青で表示されるので、「次を検索」をクリックしながら、どんどん調べていきます。
最後まで調べ終わると、「”url”が見つかりません」と表示されます。
「style(1).css」内には結局、「background:url」が存在しなかったので、ハズレです。
次は、「style.css」を開き、同じように「url」で検索していきます。
すると「background:url」が見つかりました。

見つかったら、urlの後のカッコ内の「..」以降の部分(/img_2017/template/icon08.png)をコピーします。
コピーしたら、アドレスバーにある、経済産業省のトップページのURLの後に続けてペーストし、アクセスします。

すると以下のような画像が表示されました。
これは目的の画像ではないので、ハズレです。
ハズレだったら、次に引っかかった記述をコピーして、同じようにトップページのURLの後に貼り付けて調べていきます。
一度調べた記述と同じものが何回も検索で引っかかりますが、すべて同じ画像なので、スルーして構いません。新たに登場した記述のものだけ調べればOKです。
しばらく調べていくと、以下のような記述が登場します。
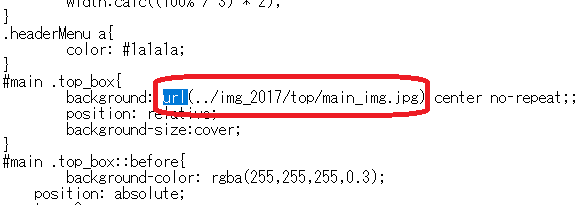
ここで得られた記述(/img_2017/top/main_img.jpg)をトップページURLの後ろに貼り付けてアクセスしていきます。
すると・・・

見事、目的の画像が表示されました。
あとは、右クリック⇒「名前を付けて画像を保存」でダウンロードするだけです。
まとめ
いかがでしたでしょうか?
今回は「Google Chrome」でやってみましたが、他のブラウザでもほぼ同様の手順で可能です。
CSSファイルが多い場合はやや大変ですが、根気強く調べ上げていけばどんなページからも画像を取得できると思います!
「Google Chrome」のデベロッパーツールを使うと実はもっと簡単にできたりするのですが、初心者には難しいので、今回は簡単な方法をお伝えしました。


コメント